はじめに
ジモティーでAndroidアプリを開発している杉田です。
この記事では、ジモティーのAndroidアプリのアーキテクチャの変遷とそれを通してチームが成長していった話を書きます。そして最後に現状とこれからの方向性に触れます。
アーキテクチャとは
プログラムの設計思想のことです。プログラムを大きな責務の単位ごとにコンポーネントで区切ります。そうすることでどこに何を書いてあるかがわかるので、チームに参加したばかりの開発者でも開発がしやすくなります。
アーキテクチャ導入前の課題
私が入社した2017年当時は、Androidチームには共通認識としてのアーキテクチャがありませんでした。それどころかほとんど全てのコード(ビジネスロジック、通信処理、DB周りの処理)はActivityに書かれていました。そのため以下のような課題がありました。
- ビジネスロジックが共通化されず、色々なActivityで重複して記述されている
- ビジネスロジックに変更が入ると、同じロジックが入っている全ての画面に変更を加える必要がある
- 重複したロジックの変更が漏れて、バグが発生する
- 複数の役割を持った超巨大なメソッドが存在し、その変更によって思わぬバグが発生する
- 例えば、巨大メソッドの最初に出てくる変数の値を変更したときに、その変数をメソッドの下の方でも参照していてバグが発生する
- Activityに色々な処理が書かれているため同時に同じActivityの改修作業をするとコンフリクトやデグレが発生する
上記の様な状態なので、チームとしてもバグが頻発する状態ですし、3年前に新人として入社した私はバグをしょっちゅう出していました。
リリースの度にリグレッションテストにかなりの工数を取られ、リリース当日はビクビクしながらリリース結果を見守っていました。リリースの度に心理的な疲労が溜まっていく状態でした。
この状態にチーム全体の危機意識が高まり、どこに何を書けば良いのか明確なルールを作ろうという動きが始まりました。
アーキテクチャ導入に向けて格闘する日々
まず最初に始めたのは、Activityに集中している処理を分離する方法を模索するところからでした。
処理の分離の単位として下記の候補が上がりました。 - GUIロジック - ビジネスロジック - 通信処理やDB周りの処理
この処理の単位で分離する方法として、GUIアーキテクチャとシステムアーキテクチャを導入したら良いのではないかという案が出て、話し合われました。
・GUIアーキテクチャ・・・主にUIにあるロジックとシステム関連のロジックを分離するためのアーキテクチャ ・システムアーキテクチャ・・・通信処理やDB周りのロジックを分離するためのアーキテクチャ
そこでGUIアーキテクチャとシステムアーキテクチャの組み合わせで注目されたのは、以下の組み合わせです。
- MVP + Clean Architecture
- MVVM + Clean Architecture
| MVP | MVVM | |
|---|---|---|
| メリット | ・Viewと表示のためのロジックの分離がシンプルにかける | ・よりモダンなアーキテクチャである。 ・データバインディングと組み合わせることで、Viewに値をセットするコードを省略できるので、より少ないコード量で実装できる |
| デメリット | ・Viewに値をセットするためのコードが必要なため、記述量が多くなる | ・実装が複雑になる。検討当時、Activityのライフサイクルと非同期処理のライフサイクルが合わない時にケアするコードが大量に必要 |
当時チームで議論した結果、MVVMの方がActivityのライフサイクルと非同期処理のライフサイクルが合わない時にケアするコードが大量に必要で、ライフサイクルをうまく合わせるための知見がなかった私たちには難しそうだということでMVPを採用することになりました。
また、システムアーキテクチャとしてClean Architectureが流行していたのと、当時アーキテクチャ導入のために参画してくれた技術顧問の方がMVP + Clean Architectureの導入経験があり、MVPの方がチームに導入しやすいということでClean Architectureを採用することになりました。
▼導入後のアーキテクチャはこんな感じになりました。
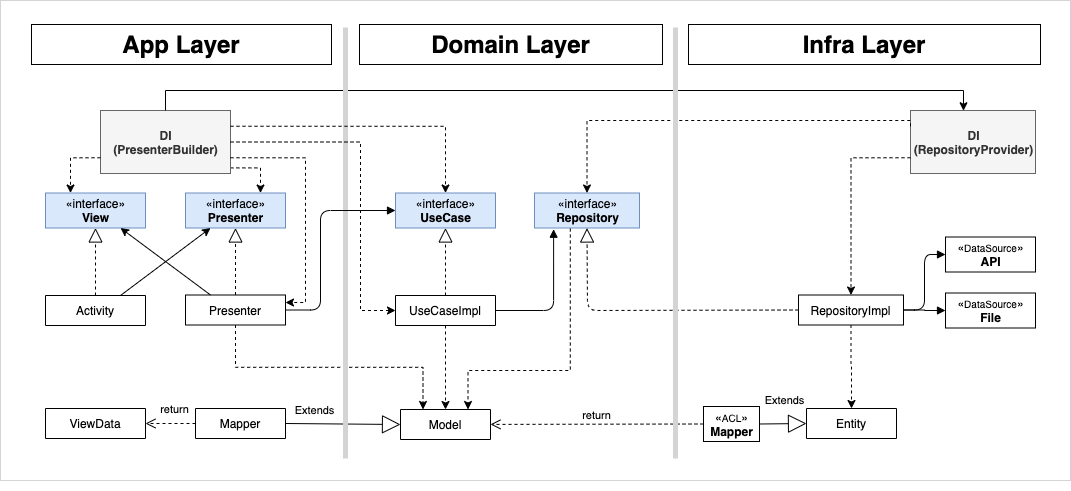
アーキテクチャの導入にあたって、全員に知見が行き渡る様に、全員が順番に工数をとって導入を行っていきました。ただし、全員が実行するにしてもメンバー間でプロダクト仕様の理解に差があるため、下記の様な分担の方針を建てました。
| 仕様の理解が深い人 | 新人などの仕様理解が浅い人 |
|---|---|
| ・ビジネス上重要な主要導線の画面 ・ビジネスロジックが複雑な画面 |
・開発規模が小さく、ビジネスロジックが少ない画面 |
最初はチームリーダーが一つの画面にアーキテクチャを導入し、その知見をwikiにまとめてチームに共有しました。その後各メンバーがアーキテクチャ導入する際には、クラス図を書いて設計レビューを行ってから実装を行いました。その結果、実装前からアーキテクチャに対してある程度の理解を持つことができたので、各自のアーキテクチャ導入がスムーズに進みました。
アーキテクチャ導入の成果
ここからはアーキテクチャを導入した結果を説明します。
アプリの品質が向上
まず、メンバー間の技術レベルを問わず、ある程度の品質を担保できるようになりました。新人だった私もアーキテクチャの概念をキャッチアップすることで、何が良いコードで何が悪いコードなのか、それがなぜなのかを理解する助けになりました。また思想が同じなので、私が書いたコードと先輩が書いたコードの品質に大きな乖離はなくなり、レビューでも先輩に対して指摘しやすくなりました。
次に、デグレによる障害が劇的に減少しました。これはプログラムをコンポーネント化することで、同じ画面を開発した時にコンフリクトを起こすことがほとんどなくなったためでした。
iOSにも同じアーキテクチャが適用できた
さらに、もう一つ想定外の成果がありました。それはプラットフォームに依存しないアーキテクチャを採用したので、iOSにも同じMVP + Clean Architectureを導入できたことでした。その結果、iOSチームとAndroidチーム間でメンバーのコンバートを行う時のスイッチングコストが激減しました。
その結果、iOSとAndroid両方を開発できる人が増えたので、プロジェクト実行時の人材配置が柔軟になりました。また、iOSチームとAndroidチーム間の意見交換が活発になり、アプリチーム全体でプロダクトをよくしていこうという思考になりました。
アーキテクチャのこれから
次の課題
Androidは最終的に、主要導線の画面だけにアーキテクチャが導入されました。まだアーキテクチャが導入されていない画面も残っています。
アーキテクチャが導入された画面にも問題がないわけではありません。緊急案件などがあり、設計せずに継ぎ足したコードがあるせいでアーキテクチャが崩れてしまっている部分もあります。設計されている画面でも、MVPを採用したことが原因で、ボイラープレートコード(お約束で重複して書かなければならないコード)が量産されていて、そのせいでコードベースが多少膨らんで生産性が良いとは言えない面もあります。
また、アーキテクチャ導入時に試行錯誤をしたコードも残っています。MVP + Clean Architectureの後に一時MVVM + Clean Architectureを目指した時期があったため、MVPの代わりにMVVMを導入した画面も存在しています。
さらに、例えば、MVP導入時に非同期通信ライブラリにRxJavaを採用しましたが、サードパーティライブラリは今後メンテナンスされ続けていく保証がありません。そのため、なるべくAndroidプラットフォーム標準のライブラリを活用したいところです。
つまり、プロダクト全体としてみるとアーキテクチャがバラバラになっていて、MVPが適用されている画面に関してはボイラープレートが多いため生産性が上がりきっておらず、中には歴史的経緯でアーキテクチャ化した後にコードの設計が崩れてしまっている部分があるのです。
これからの方針
これからの方針ですが、Androidチームは崩れてしまったコードベースを改善するためにMVVM + Clean Architectureに切り替えていく検討を始めています。
2017年にアーキテクチャを導入した時に比べると、Androidプラットフォームは大きく進化しました。当時は、MVVMへのAndroidプラットフォームのサポートがなく、技術的に導入が難しかったのですが、現在はAAC(Android Architecture Components)を導入することで比較的簡単にMVVMを導入可能になっています。
MVPからMVVMにアーキテクチャを切り替え、全画面にMVVMを適用することによって、下記の課題が解決することが見込まれます。
- アーキテクチャの混在によって、コードの見通しが悪くなる
- MVPを採用していることによる大量のボイラープレート
- Androidプラットフォーム標準のライブラリを活用できていない
アーキテクチャの混在によって、コードの見通しが悪くなる
これは説明しなくてもご理解いただけると思いますが、MVVMにアーキテクチャが統一されるのでコードの見通しは良くなります。
MVPを採用していることによる大量のボイラープレート
MVPを採用したため、Viewへの値の設定や通信処理とActivityのライフサイクルの調整の処理が大量にボイラープレートとして書かれています。
AACを導入することで上記の様なボイラープレートをかなり削減できることが見込まれます。
Androidプラットフォーム標準のライブラリを活用できていない
非同期処理にRxJavaを使っていましたが、AACとKotlinのコルーチンを組み合わせることで代替できるなど、2017年当時にサードパーティーライブラリに頼らざるを得なかった機能についても標準ライブラリでかなり補える様になっています。
その他
MVVMの導入時に、先に述べた継ぎ足されたコードの設計も見直し、より開発がしやすいコードに生まれ変わらせていく予定です。
最後に:みなさん待ってます!
上記の様な方針で進めて、開発生産性をあげ、サービスの成長にガンガン貢献できるチームになっていきます!
Androidチームでは、この今後の改善に一緒に取り組んでくれる方を募集しています!
一緒に頑張りましょう!!
弊社では一緒にプロダクトを改善していただける仲間を探しています!
こちらでお気軽にお声がけください!





 進行中のスプリントが表示されている画面で、進行中のタスクはそれぞれ誰が担当しているのか一目瞭然!
進行中のスプリントが表示されている画面で、進行中のタスクはそれぞれ誰が担当しているのか一目瞭然! 進行中のスプリントでメンバーがどのようなアサイン状況か一覧できるのでスプリントにどれだけタスクを入れられるか判断しやすくなりました
進行中のスプリントでメンバーがどのようなアサイン状況か一覧できるのでスプリントにどれだけタスクを入れられるか判断しやすくなりました 各エピックへ関連づけられたタスクを、エピック毎に把握しやすくなり手薄になっている観点や今後の施策立案の適正さの維持に役立っています
各エピックへ関連づけられたタスクを、エピック毎に把握しやすくなり手薄になっている観点や今後の施策立案の適正さの維持に役立っています