ジモティーでサーバサイドとインフラを担当している吉田です。
この前、初めて献血に行ってきました。直前の検査で手汗に気づいたスタッフから「初めてで緊張されていますか?今ならまだ止められますよ。」と声をかけられたのが、今年一番緊張した出来事です。2023年はいろんな新しい事にチャレンジする年にしたいと思います。
さて、今回は Danger の問題を発見し、報告および修正した事例を紹介します。Danger には JavaScript 版や Swift 版もあるのですが、ここでは Ruby 版について記載します。また、Danger のメンテナである Orta Therox 氏には、公開の許可を頂いています。
概要
バージョン 8.6.0 より前の Danger では、細工された名前のブランチで実行されると、任意のコマンドを実行できる問題がありました。すでに 8.6.0 以降では修正されています。
Danger は主にリモートの CI 環境で実行されるので RCE (Remote Code Execution) もしくはコマンドインジェクションの脆弱性に該当する可能性があると考えますが、Security Advisory の作成や CVE の申請はありませんでした。
Danger とは?
Danger は CI 上で、特定のルールにしたがったコードレビューを自動化するためのソフトウェアです。
例えば、プラグインと連携することで Rubocop や Breakman といった静的解析ツールによる指摘事項を GitHub Pull Request にコメントする事が可能です。一部の制限はあるものの、GitHub だけでなく GitLab や Bitbucket などの SCM (Source Control Management) でも動作しますし、JavaScript や Swift など他のプログラミング言語にも対応しています。
問題
環境
ここでは次の環境を想定しています。
- Danger のバージョン
- 8.5.0
- SCM
- GitHub(非 Enterprise)
- CI 環境
- GitHub Actions (GitHub-hosted runner)
- Runner Image は
ubuntu-22.04
準備
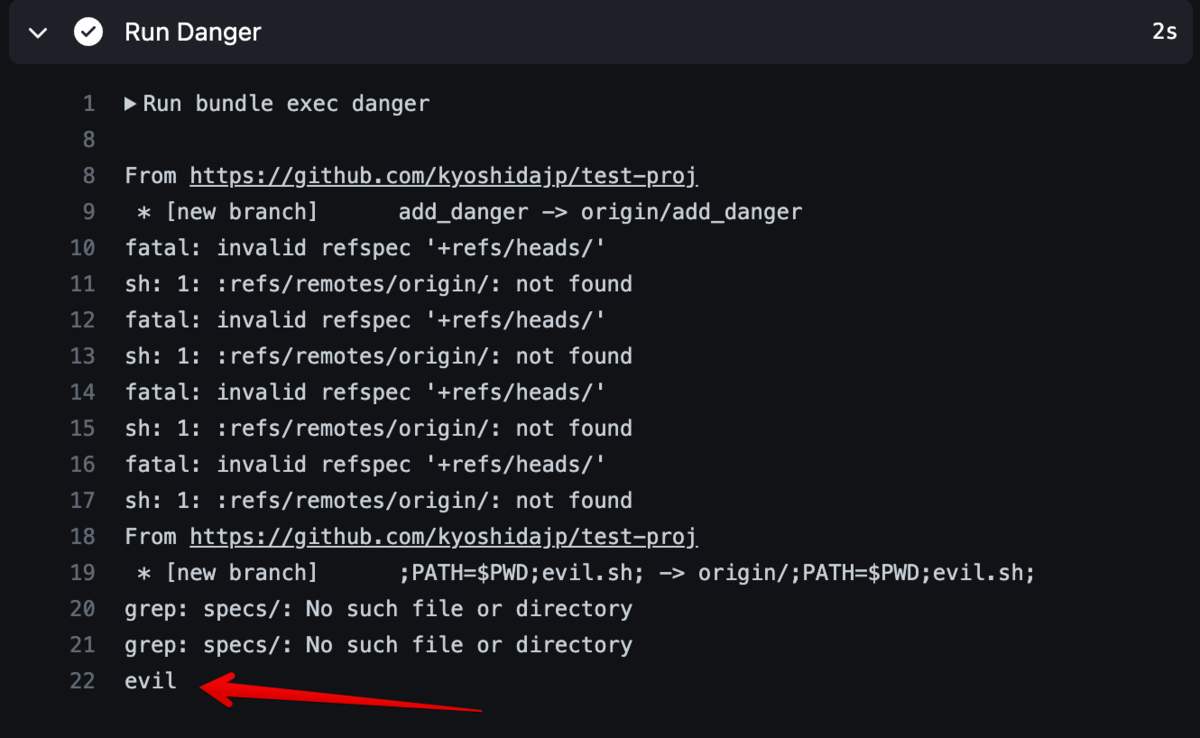
適当なリポジトリを準備し、名前を ;PATH=$PWD;evil.sh; としてブランチを作成します。
$ git switch -c ';PATH=$PWD;evil.sh;'
次に、任意のコマンドを実行するシェルスクリプト evil.sh を作成します。
#!/bin/bash export PATH=$PATH:/sbin:/bin:/usr/bin # 任意のコマンドの例 echo "evil" > evil.txt
GitHub Actions のワークフローファイルに対して、Pull Request 作成時に次のコマンドを実行する指定を行います。その他の設定については説明を省略します。
bundle exec danger cat evil.txt
最後に evil.sh およびワークフローファイルをコミットして、Pull Request を作成します。
実行と確認
GitHub Actions で Danger の実行が完了すると、ログに evil が出力されます。これにより evil.sh で実行したコマンドの成功が確認できます。
影響
前提として、公開設定がプライベートになっているリポジトリは外部のユーザがアクセスできないため、影響を受ける可能性は非常に低いと思います。
そうでない場合、具体な影響の例として次が考えられます。
- Danger を実行する環境の破壊
- リポジトリのコードの追加、変更、削除
- Danger の実行ユーザに権限があった場合
- シークレットを外部に送信
- Danger の実行環境からアクセス可能な外部環境へのアクセス
- 例えば、CI からテストデータ参照のため社内 AWS 環境へアクセスを許可しているケース
実際は外部のユーザがそのまま CI を実行できないようにブロックされているケースが多いです。Danger 自体の GitHub Actions ワークフローも、承認が行われてから実行される運用になっていました。
しかし、たとえ承認フローが設定されていても、レビューで細工されたコードを見落とすと実行が成功してしまいます。今回の例ではシェルスクリプトでしたが、バイナリファイルだったり、別の Pull Request で入った(入る)コードを実行する処理が難読化されていると、見落としてしまう可能性は残ります。
原因
修正前の 8.5.0 を例に、原因となったコードについて解説します。
まず、Danger の実行の過程で Danger::GitRepo クラスの git_fetch_branch_to_depth メソッドが呼び出されます。
def git_fetch_branch_to_depth(branch, depth) exec("fetch --depth=#{depth} --prune origin +refs/heads/#{branch}:refs/remotes/origin/#{branch}") end
このメソッドでは、第一引数の branch と第二引数の depth から作成される文字列が同じクラスの exec メソッドに string として渡されます。
def exec(string) require "open3" Dir.chdir(self.folder || ".") do Open3.popen2(default_env, "git #{string}") do |_stdin, stdout, _wait_thr| # (省略)
上記コードから、string は git コマンドのオプションとして期待された文字列になる事が分かります。
git_fetch_branch_to_depth メソッドの branch はその名の通りブランチ名です。ブランチ名には git で許可された任意の文字列を指定できます。参考までに、ブランチ名に関する制限は Git - git-check-ref-format Documentation から確認できます。
もし depth が 20 だと仮定すると、branch の値は ;PATH=$PWD;evil.sh; なので 、次の文字列
"fetch --depth=#{depth} --prune origin +refs/heads/#{branch}:refs/remotes/origin/#{branch}"
を文字列展開すると次になります。
fetch --depth=20 --prune origin +refs/heads/;PATH=$PWD;evil.sh;:refs/remotes/origin/;PATH=$PWD;evil.sh;
これは Danger::GitRepo#exec 内の Open3.popen2 によって、次のコマンドが連続して実行される事になります。
git fetch --depth=20 --prune origin +refs/heads/PATH=$PWDevil.sh:refs/remotes/origin/PATH=$PWDevil.sh
問題となるのは3と6のコマンドです。
PATH=$PWD は環境変数の PATH にカレントディレクトリを指定しています。ここには evil.sh が存在するため、evil.sh に指定した任意のコマンドが実行できてしまいます。
また、別のファイルを実行しなくても、例えばブランチ名を ;echo${IFS}"hello"; とすると結果的に echo hello を実行する事が出来ます。これは次のドキュメントを読んで知りました。
ブランチ名のみにインジェクションする方法は、文字やその長さに制限がある一方で、レビュー時に見落とされる可能性が比較的上がると思います。
報告と修正
Danger のソースコードを読んでいて、偶然この問題に気づきました。発見した当初は具体的に問題となる方法が思いつかず、違和感がありつつもそのままにしていました。しばらくして、今となっては何がきっかけになったか忘れたのですが、その方法が思いついた次第です。
Danger の GitHub リポジトリにはセキュリティレポートの窓口がなかったため、メンテナの Orta Therox 氏に Twitter の DM で報告しました。
その結果、「Issue に該当する」と返答をもらいましたが、数ヶ月経過しても特に動きがありませんでした。念の為再度連絡して Issue の作成により問題が公開される事を説明し、その許可をもらったため、GitHub のリポジトリ上に Issue を作成しました。
また、あわせて修正する PR を作成しました。
- Fix Remote Code Execution vulnerability by kyoshidajp · Pull Request #1360 · danger/danger
- git のオプション文字列をいったん
で分割した配列にして、展開したものをOpen3.popen2に渡すようにした
- git のオプション文字列をいったん
すぐにマージされ、8.6.0 としてリリースされました。
最後に
Danger に存在していた問題について解説し、報告および修正した事例を紹介しました。
CI 環境は、プロダクトコードと同様に常にセキュアに保つ必要があります。次は GitHub Actions に関する資料ですが、攻撃の例や、もし被害を受けた時の影響を軽減するベストプラクティスなどが記載されており、他の CI 環境でも非常に参考になると思いますので紹介しておきます。
また、ジモティーではエンジニアを積極的に採用しています。
ご興味のある方はこちらをご覧ください。
https://jmty.co.jp/recruit_top/
弊社では一緒にプロダクトを改善していただける仲間を探しています!
こちらでお気軽にお声がけください!