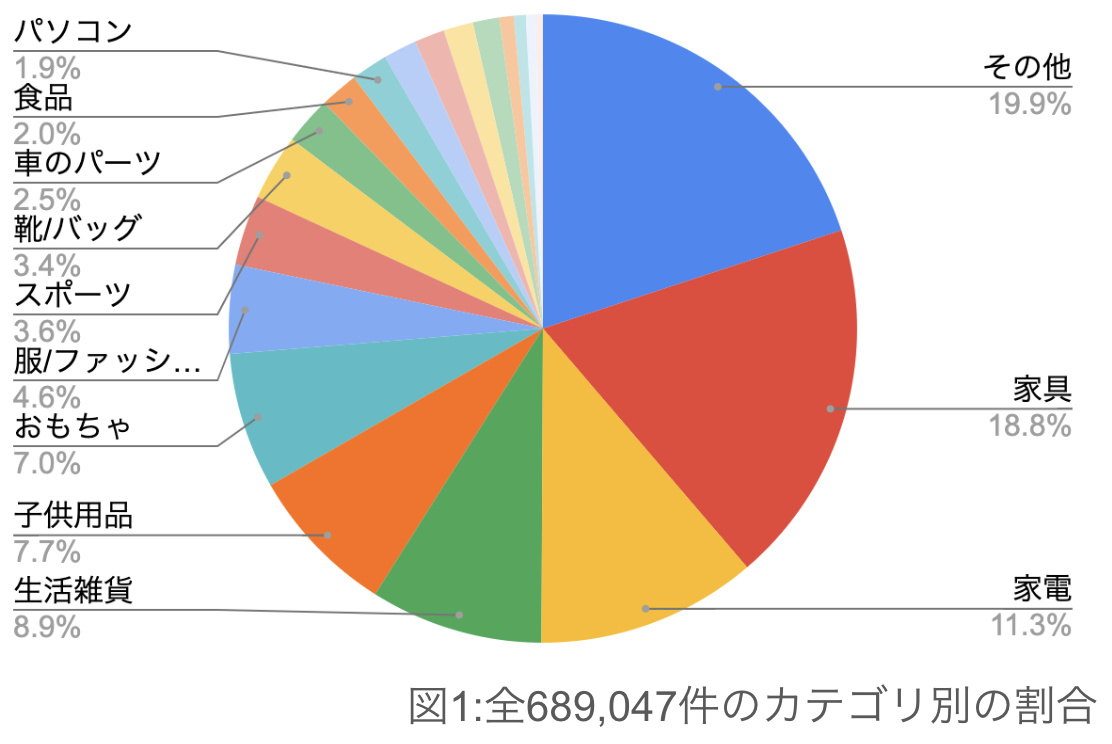
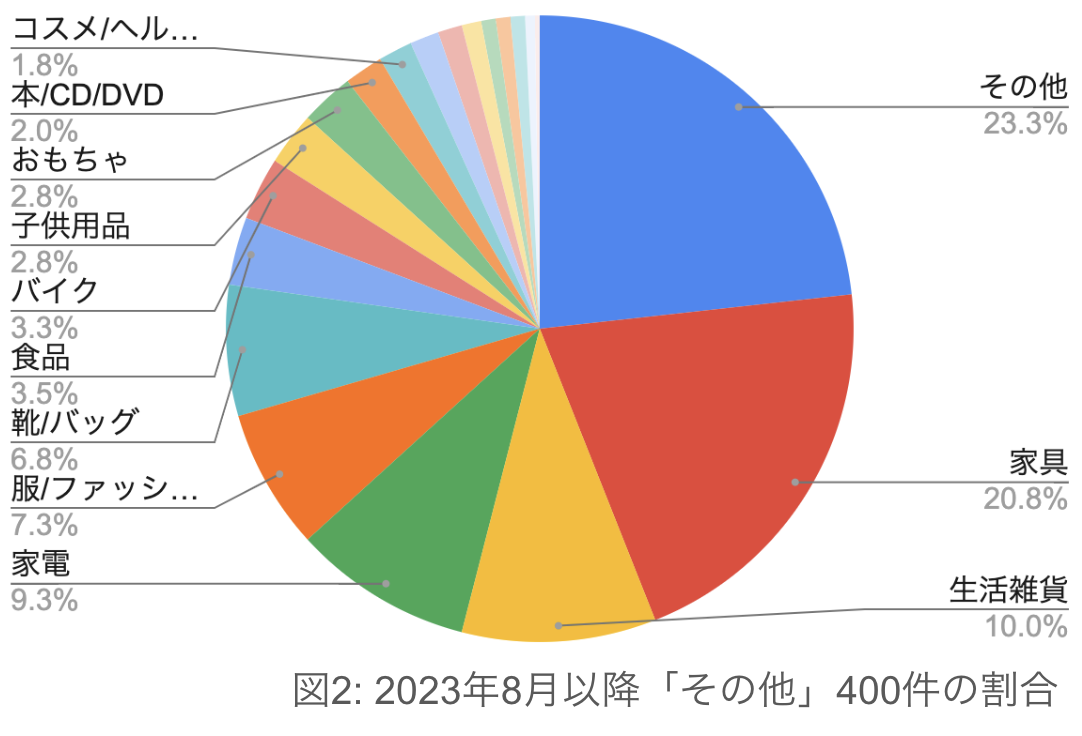
こんにちは。
iOS チームの池沢です。
最近、桃鉄( 2 ではなく定番の方 )でついに 100 年プレイをやってみました。
途中のデストロイ号1に何度も心を折られましたが、 68 年目になんとか全物件購入・全駅踏破を達成しました。 30 年くらい残ってますが、目標を失ってしまい結局最後まではプレイできていません。
桃鉄の話はさておき、今回は iOS アプリにおける証明書管理について書きます。
今までは年に 1 回証明書を更新する必要がありマニュアルを読み返してましたが、その作業から開放された喜びが伝わる記事になっていましたら幸いです。
背景
iOS アプリを App Store で公開したり社内に配布するためには、配布証明書と呼ばれるものを使ってアプリに署名する必要があります。
署名がされていないアプリは、 App Store Connect へアップロード出来ず、社内に配布しても iOS がそのアプリを信頼出来ないものと判定して開くことが出来ません。
課題
署名に使われる配布証明書ですが、生成されてから有効期限が 1 年しかありません。
そのため毎年 1 回、新しい配布証明書を生成する必要があります。
しかし、配布証明書の生成アプリは普段使わないため使い方を覚えられず、弊社内で前に作成されたマニュアルを必ず読み返す必要がありました。
そんな中、 Apple が 2021 年に Cloud-managed certificates というものをリリースしました。
これは証明書の発行や管理をすべてクラウドサービス側が行ってくれる2もので、上記の課題を解決するべく移行を行いました。

やったこと
App Store Connect で API キーを発行
App Store Connect で、 API キーを作成します。
ユーザーとアクセス > 統合 タブに移動し、+ ボタンからキーを作成出来ます。
role は Admin である必要があります。
作成したキーの他に、キー ID 、 Issuer ID を使うことになります。

ExportOptions.plist を作成
以下のファイルを作成します。私はプロジェクト直下に作成しました。
DESTINATION_METHOD , EXPORT_METHOD , APPLE_TEAM_ID は変数として用途ごとに設定しています。
DESTINATION_METHOD
upload : ipa を作成し、 App Store Connect へアップロードする
export : ipa を作成するのみ
EXPORT_METHOD
app-store : App Store Connect へのアップロード用
adhoc : QA 用
enterprise : In-House 用
development : 開発用
APPLE_TEAM_ID Apple Developer Program を契約しているチーム ID
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>destination</key>
<string>DESTINATION_METHOD</string>
<key>manageAppVersionAndBuildNumber</key>
<false/>
<key>method</key>
<string>EXPORT_METHOD</string>
<key>signingStyle</key>
<string>automatic</string>
<key>stripSwiftSymbols</key>
<true/>
<key>teamID</key>
<string>APPLE_TEAM_ID</string>
<key>uploadSymbols</key>
<true/>
</dict>
</plist>
署名無しで .xcarchive を作成
xcodebuild archive コマンドで .xcarchive を作成します。
.ipa を作成するにおいてこのタイミングでの署名は必須ではないため、 CODE_SIGNING_REQUIRED=NO と CODE_SIGNING_ALLOWED=NO を指定して署名無しでアーカイブします。
$ xcodebuild archive \
-workspace ${ .xcworkspace のパス } \
-scheme ${ スキーム名 } \
-configuration ${ Build Configuration 名 } \
-archivePath ${ .xcarchive の生成先パス } \
CODE_SIGNING_REQUIRED=NO \
CODE_SIGNING_ALLOWED=NO \
| xcpretty
Entitlements をビルドに埋め込む
署名なしで作成した .xcarchive には Entitlements 情報が含まれません。
そのため Push 通知や Sign in with Apple の機能を含むアプリの場合は、それらの機能が使えなくなってしまいます。
codesign コマンドを使って .xcarchive に Entitlements 情報を上書きすることで、 Push 通知や Sign in with Apple が使える .ipa に作成することが出来ます。
$ codesign \
--entitlements ${ .entitlements のパス} \
--force \
--sign "-" ${ .xcarchive 内の .app のパス}
API キーを用いて .ipa を作成
xcodebuild -exportArchive コマンドで .ipa を作成します。最初の方で作成した API キーや ExportOptions.plist を使用します。
$ xcodebuild -exportArchive \
-archivePath ${ .xcarchive のパス } \
-exportPath ${ .ipa の生成先パス } \
-exportOptionsPlist ${ ExportOptions.plist のパス } \
-allowProvisioningUpdates \
-authenticationKeyID ${ API キーのキー ID } \
-authenticationKeyIssuerID ${ API キーの Issuer ID } \
-authenticationKeyPath ${ API キーのパス } \
| xcpretty
ipa が問題ないか確認
最後に作成した .ipa が問題ないかを確認します。
確認するためには、 .ipa の生成先パスに一緒に作成されている DistributionSummary.plist を確認します。
certificate が Cloud Managed Apple Distribution になっていて、 entitlements に aps-environment や com.apple.developer.applesignin が含まれていれば問題ありません。

まとめ
iOS アプリの署名に使うための配布証明書を Cloud-managed certificates に移行する手順を記しました。
これで年に 1 回の作業時間がなくなったので、私はその時間で桃鉄の残り 30 年をプレイしたいと思います3。
最後に
弊社では一緒にプロダクトを改善していただける仲間を探しています! こちらでお気軽にお声がけください! https://jmty.co.jp/recruit_top/