はじめに
北見工業大学大学院にて自然言語処理の研究を行っております、重延(シゲノブ)と申します。
全国で140名程度しかいない珍しい苗字ですので、覚えていただければ幸いです。
2024年8月より株式会社ジモティーにて、インターン生としてエンジニアリング業務に従事させていただいております。
今回はサマーインターンでの自身の取り組みについて、テックブログとしてまとめたいと思います。
今回のサマーインターンでは研究室のメンバー3名で参加させていただきました。
インターンの目標として与えられたのは、各部署の課題を自分たちの研究で得た知見を活かして解決するということでした。
まず初めに課題のヒアリングを行い、その結果として以下のようなテーマが挙がりました。
- その他カテゴリに埋もれている投稿の再分類
- 距離に応じて商品を提案する仕組み作り
- 問い合わせ数の予測
- 取引完了に至らない理由の分析
- 類似投稿やNG投稿の自動チェック
- 外部連絡先を交換していないかの自動チェック
この中で私は「その他カテゴリに埋もれている投稿の再分類」という課題に着目し、その解決をサマーインターンの目標と定めました。
背景と目的
ユーザーが売買取引を行うにあたって商品カテゴリを付与する際に、以下のような課題が指摘されていました。
- 適切なカテゴリが見つけられない
- カテゴリ選択が手間に感じられる
その結果、投稿がその他カテゴリに分類されるケースが多く発生していました。
これまでにも画像からカテゴリを推定してサジェストする仕組みなど、いくつかの対策が取られてきました。
しかし、それでもその他カテゴリの投稿割合に大きな変化は見られなかったとのことです。
事前調査として2024年8月の全売買投稿件数(689,047件)のカテゴリ毎の割合を示します。
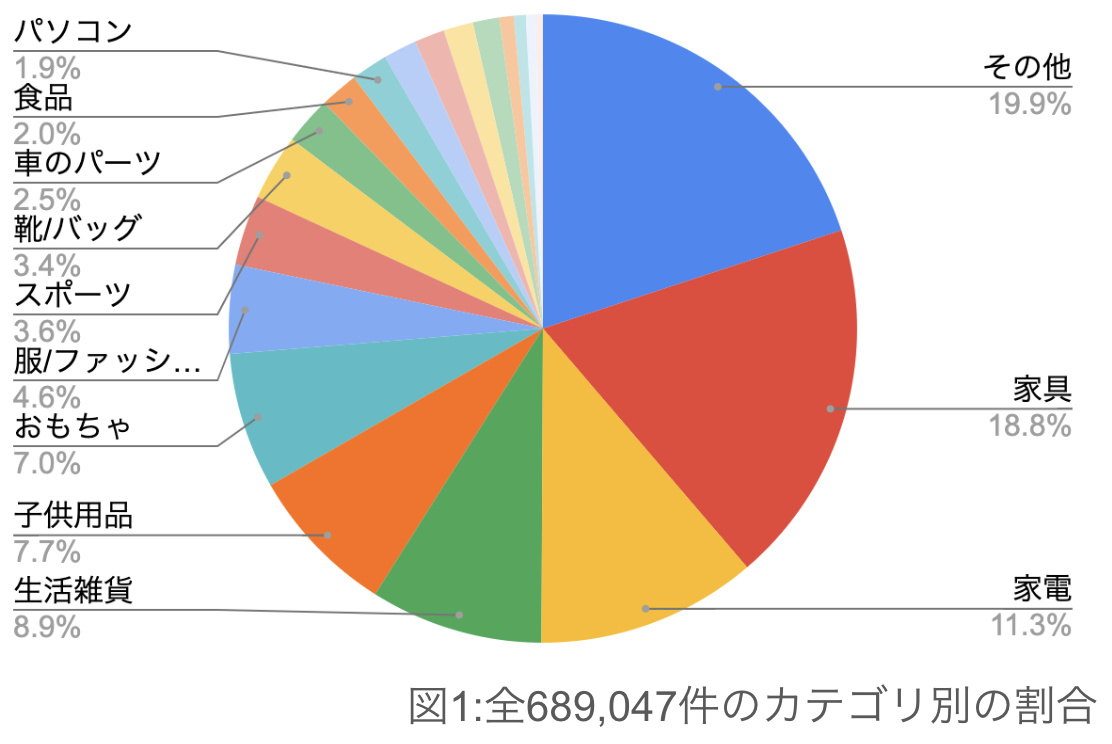
このようにその他カテゴリが最多となっており、割合にして19.9%となっております。
次にその他カテゴリにどれほど誤分類されているかを調査します。
2023年8月以降のその他カテゴリ投稿からランダムに400件抽出し、私の判断によってカテゴリを再度振り分けた結果を以下に示します。
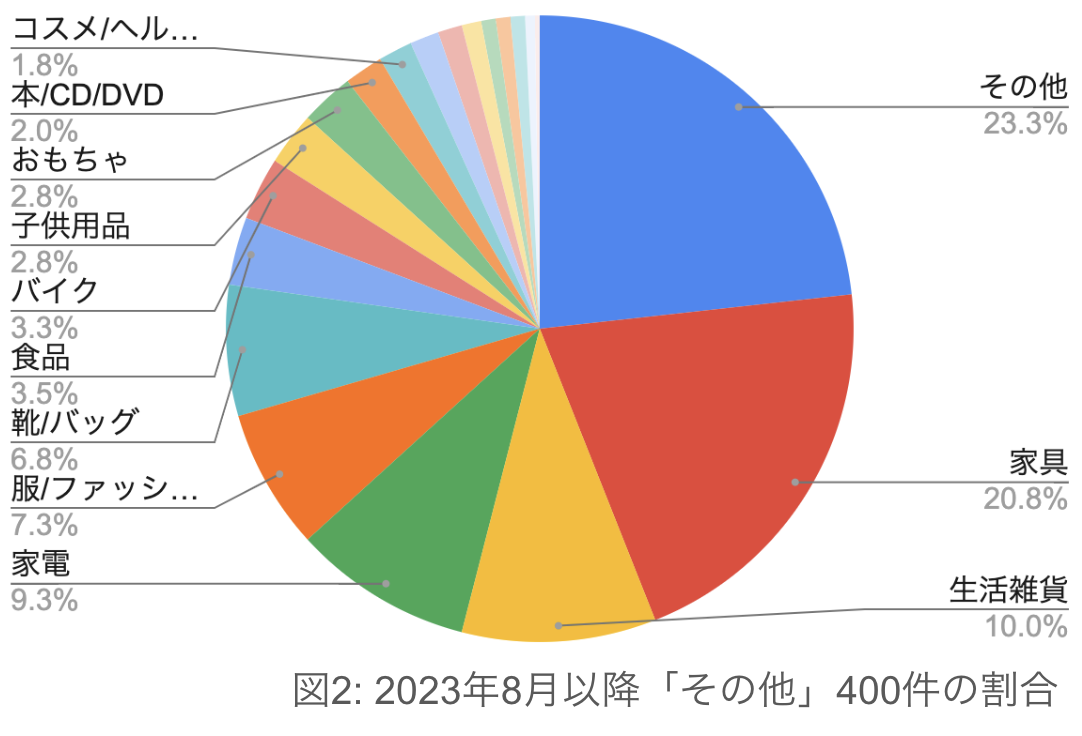
- 「その他」カテゴリに分類された投稿のうち、76.7%が別のカテゴリに振り分け可能だった。
- 全投稿におけるカテゴリ割合と類似しており、「その他」カテゴリが正しく機能していないことを示唆している。
これは全投稿の割合から考えると月ごとに約10万件がその他カテゴリに埋もれてしまい、見つけられにくくなっている状況であると言えます。
これにより検索精度の低下や成約機会の喪失、データ分析精度の低下といった問題が生じる恐れがあります。
そこでその他カテゴリをあらためてチェックし、テキストベースでのカテゴリの再分類ができないかを考察します。
手法
このようなマルチラベル分類における手法は、大別すると以下が考えられます。
- 辞書ベース分類
- 特定のカテゴリに対応する単語をあらかじめ定義、それに基づき分類を行う。
- 従来型の機械学習モデルによる分類
- SVMやソフトマックス回帰などの機械学習アルゴリズムを用いて、特徴量に基づき分類を行う。
- 大規模言語モデル(LLM)を使用した分類
- BERTなどの事前学習済みモデルを用いて、ゼロショット分類やファインチューニングによる分類を行う。
今回その他カテゴリのデータを確認すると固有名詞が多く、辞書ベースの分類は困難であると感じられました。
またそれぞれ商品名などは簡潔に書かれており、商品の特徴は強く現れると考えられます。
しかし使用感やサイズ、状態などの周辺情報も利用できると考え、文脈の理解が得意なTransformerモデルを使用した分類を行うことに決定しました。

はじめにゼロショット分類を行いどの程度分類が可能かを調査し、その上でファインチューニングを行い比較します。
実験結果
評価指標として以下の5つを使用します。
・正解率(Accuracy):正、負と予測したデータが正解している割合
・Top3-Accuracy:予測した上位3つまでが正解している割合
・適合率(Precision):正と予測したデータが、実際に正である割合
・再現率(Recall):実際に正であるデータが、正と予測された割合
・F値(F-measure):再現率と適合率の調和平均
教師なし学習
- 使用モデル:MoritzLaurer/mDeBERTa-v3-base-xnli-multilingual-nli-2mil7
- マルチリンガルに対応したNLI(自然言語推論)に特化したモデルの一つであり、マルチラベルのゼロショット分類に広く用いられているため使用
- データセット:事前アノテーションによってその他から別カテゴリに振り分けられた307件
- ラベル:その他以外の19カテゴリ
ゼロショット分類結果
| 使用データ | Acc | Top-3 Acc | Prec | Rec | F1 |
|---|---|---|---|---|---|
| タイトルのみ | 0.494 | 0.713 | 0.522 | 0.597 | 0.448 |
| タイトル+テキスト | 0.492 | 0.736 | 0.513 | 0.602 | 0.482 |
結果として全文を使用した場合の方が高スコアとなり、そのF1スコアは0.482とあまり高い数値とはなりませんでした。
エラー分析をすると、以下の例のように複数要素が混じった商品においてミスが多く見られました。
よってファインチューニングを行い、カテゴリへの理解を深める他、タイトルへの重み付けなどの対策が考えられます。
| Title | Text | 予測ラベル | 正解ラベル |
|---|---|---|---|
| ピカチュウのポーチ | カバンの中でパイナップルジュースを爆発させてしまったときにカバンに入っていたものなので、ニオイと汚れがかなりあります。... | 食品 | 靴/バッグ |
教師あり学習
次に、ファインチューニングを行った分類結果を示します。
- 使用モデル:tohoku-nlp/bert-base-japanese-whole-word-masking
- 日本語に特化し、Whole Word Maskingを活用した事前学習済みモデルであり、文脈理解に優れているもの
- データセット:44697件
- その他以外の19カテゴリが均等になるようにランダム抽出し、データ整形をした上で利用
- ラベル:その他以外の19カテゴリ
ファインチューニング後の分類結果
| 学習率 | Acc | Top-3 Acc | Prec | Rec | F1 |
|---|---|---|---|---|---|
| 1e-5 | 0.779 | 0.889 | 0.784 | 0.779 | 0.781 |
| 2e-5 | 0.781 | 0.899 | 0.789 | 0.784 | 0.785 |
F1スコアは最高で0.785とかなり大きな数値の向上が見られました。
これは投稿の傾向を理解し、カテゴリ間の関係性を深く理解できるようになった結果であると考えられます。
また、今回はタイトルの重み付けやパラメータの微調整が不十分であるため、更なる精度向上が期待できます。
まとめ
その他カテゴリに誤分類された投稿を、約8割弱の確率で分類することができました。
これにより、課題解決の一歩を踏み出す成果を得られたと考えられます。
今後はカテゴリの修正方法を工夫するとともに、ファインチューニングの手法そのものを改善することでより高精度な分類が可能になると考えられます。
今後は私自身がこのモデルの実装を担当する運びとなりました。
実際の開発環境でモデルを運用する貴重な経験を活かし、さらなるスキル向上に努めていきたいと思います。