はじめまして、ジモティーでCTOをしている鈴木です。先日、弊社で構築したデータ分析基盤について紹介します。
背景
仮説の妥当性の担保や、施策の効果検証のためにデータ分析は必須です。 最近ジモティーではビジネスサイドのメンバーが増えてきたことで、社内でのデータ分析が急速に進むようになりました。
これまでは、ディレクターがデータ抽出を依頼→エンジニアが指定されたデータをCSVに出力して渡すという形になっていました。 データの抽出の依頼が週に5、6件発生し、1件毎にエンジニアの工数が数時間取られるという状況です。
これによりエンジニアは本来担当しているタスクが遅延し、 ディレクターはデータ分析のためにエンジニアの作業を待たなければならないという状況でした。
これら課題を解決するために以下をゴールとしてデータ分析基盤を構築します。
ビジネスサイドのメンバーにSQLを習得してもらい、自分でデータ分析できる
またジモティーではメインのDBにMongoDBを採用しています。 MongoDBはNoSQLですので、当然そのままではSQLを叩けません。
ということでMongoDBからembulkを用いてRedshiftにデータを投入し、Redashで可視化することにします。
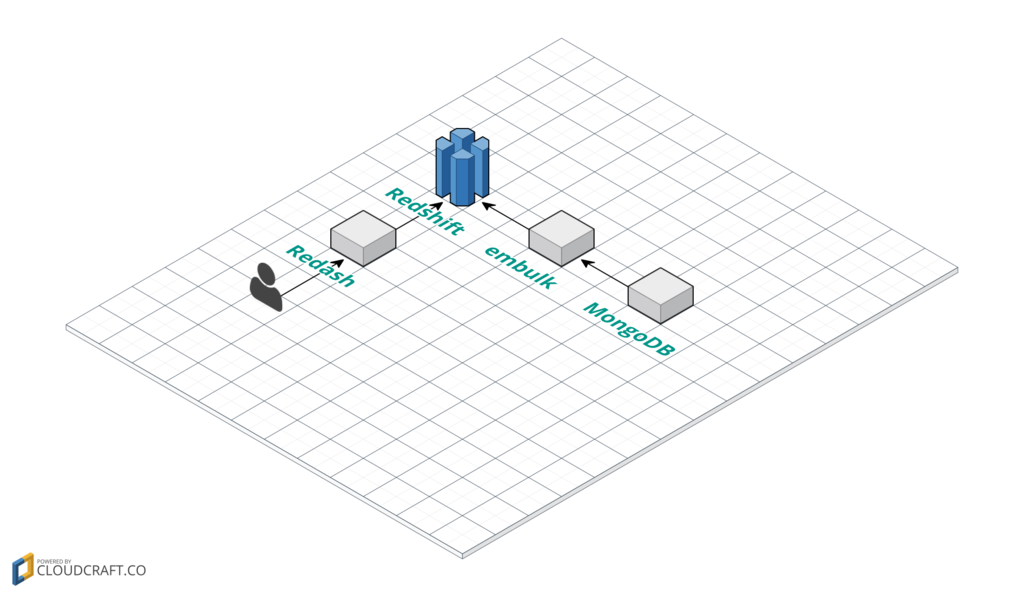
Redshift
AWSの提供するデータウェアハウスです。 PostgreSQLをベースとしていますので、PostgreSQL互換のSQLを実行できます。 RedshiftとPostgreSQLの細かい違いはこちらを参照してください。
他の選択肢としてはBigQuery、TreasureDataがありますが以下の点を考慮してRedshiftを採用しました。
- AWSで構築している既存サービスとの親和性
- クエリに依存せず固定額(SQLに不慣れなメンバーも実行する前提なので)
- データ量がまだそれほど多くないので安価に始められる
Redshiftクラスタの構築方法については以下のマニュアルを参照してください。
Amazon Redshift の概念的な概要 - Amazon Redshift
Redash
オープンソースのデータ可視化ツールです。標準で以下のような機能を備えています。 ※ v1.0からRe:dash→Redashに表記が変わりました。
- 複数のデータソースに対応→ 対応データソース一覧
- ビジュアライズ … クエリの結果から円グラフ、折れ線グラフ、散布図などを描画
- スケジューリング ... 保存したクエリにスケジュールを設定し定時実行できる
AWSアカウントをお持ちであれば公式からAMIが提供されていますので1分で起動できます。 http://docs.redash.io/en/latest/setup.html
起動後にブラウザでRedashインスタンスにアクセスし、データソースを設定します。
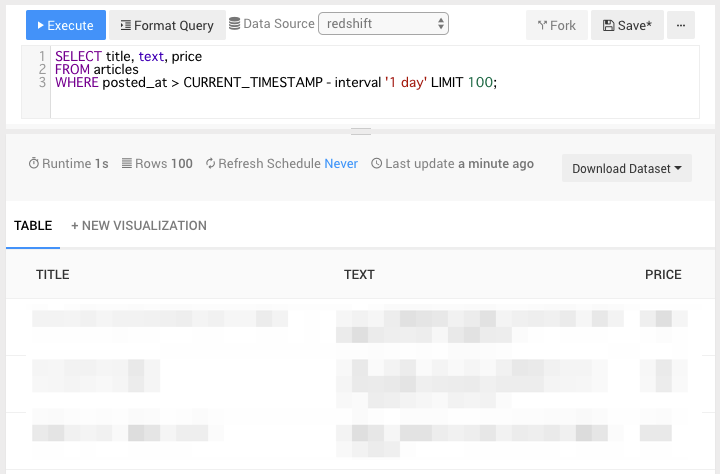
以下のようにRedash経由でSQLを実行することができます。※テーブル名、列名等はダミーです。
ちなみにRedashはデータソースにMongoDBを指定することもできますが、 非エンジニアにMongoDBのクエリを習得してもらうのは学習コストが高すぎると判断して止めました。
embulk
embulkはオープンソースのデータ転送ソフトウェアです。 プラグイン機構によって様々なデータベース/データストレージ/ファイルフォーマットに対応できます。 今回はMongoDBからRedshiftへのデータのインポートに利用します。
プラグインの一覧はこちらです。→Embulk: Plugins
今回はmongodbから取得したデータをRedshiftに投入したいので、以下のプラグインを利用します。
また、MongoDBのデータはJSON形式で取り込まれますがそれをRedshiftに投入できるように列形式に展開する必要があります。 そのために以下のプラグインも追加します。
導入効果
導入から2ヶ月経過しましたが、現在200近いクエリが登録されていて、その大半がビジネスサイドのメンバーのものです。 エンジニアがデータ抽出に工数を割くこともほぼ無くなりました。 データ分析の速度は格段に向上したと言えるでしょう。
活用を促進するために、SQLの講義を行ったり、参考書籍として「10年戦えるデータ分析入門」を紹介するといった啓蒙活動も行っています。
今後の展望
今後は以下のことにも挑戦していきたいと思います。
- 現状、DBに保存されているデータだけが対象となっているが、サーバーログやGoogle AnalyticsのデータもRedash上で分析可能にする
- Airbnb製のデータ可視化ツール Superset を試す
弊社では一緒にプロダクトを改善していただける仲間を探しています!
こちらでお気軽にお声がけください!