インフラエンジニアの佐藤です。
今回はEC2上で実行していたバッチ処理をコンテナ上で実行させるようにしたのでその話を書いていきます。
コンテナ化するにあたりマネージドサービスを活用してサーバレスに運用していきます。
利用したサービスや移行にあたっての問題、活用事例を紹介していきます。
背景
用途を分けて2台のバッチサーバで運用していましたが、Rubyのアップデートを始め各種ミドルウェアの更新をする度に、新しいAMIを作成してバッチサーバの入れ替え作業を実施していました。
AMIを作成する時間が長かったり、入れ替えに伴う工程が多かったりといくつかの負債がありコンテナを導入することで運用コストを下げようといった狙いからスタートしました。
まずは、入れ替え頻度が高めで運用コストがかかっているサーバロールを選定しました。
主に下記3つが対象となります。
- ウェブサーバ
- 非同期処理サーバ
- バッチサーバ
比較的容易に変更できそうなバッチサーバのコンテナから実施することにしました。
利用したマネージドサービス
- AWS Fargate
- AWS Step Functions
- AWS Lambda
- CloudWatch Logs Insights
Fargate
バッチ処理を動作させるコンテナ基盤として利用しました。
Cloudwatch Events多重起動問題
タスクを定期実行できるスケジュール機能があり、Cloudwatch Eventsの仕組みが使われています。
こちらをCronの代替として利用することも可能ですが、同じタスクが複数回トリガーされる可能性があります。
バッチ処理では該当時間帯に一度の実行しか許容できない処理も存在するので、安易にこのスケジュール機能を使うことはできませんでした。
同じタスクの多重起動を回避するためタCron専用のサーバを用意することにしました。
※後日、Step Functionsを用いてこの問題を回避できることが分かったので、いずれはそちらに切り替えたいと思っています。
参考: 重複実行を許容しないステートマシンを構築
固定IP対策
EC2インスタンスに固定IPを付与していました。
特定のサーバと通信する際に利用していますが、Fargateタスクとして実行する場合にはランダムな可変IPが付与されてしまいます。
回避策としては下記のようなパターンなどが挙げられると思います。
- NAT Gatewayを利用する
- Proxyサーバを経由する
- 可変IPを許容できる仕組みに切り替える
今回は可変IPを許容できる仕組みへの切り替えました。
固定IPに依存している処理は数が少なかったのでSecurityGroupを利用したり、処理の切り分けをして一部でのみ固定IPで通信するようにしました。
依存している処理が多ければNAT GatewayやProxy経由での通信が良さそうに思いますが、費用や運用コスト面を考えたところ可変IPに対応するようにしました。
Step FunctionsとLambda
コンテナの起動に失敗した際のワークフローを作成するために利用しました。
稀にFargateタスクの起動に失敗することがあります。
失敗したタスクのStopped Reasonを確認すると、下記のようなエラー例を確認することができます。
ResourceInitializationError: failed to configure ENI: failed to setup regular eni: context deadline exceededTimeout waiting for EphemeralStorage provisioning to complete.Timeout waiting for network interface provisioning to complete.
これらの StopCode を確認してみると TaskFailedToStart となっており、タスクの起動自体に失敗していることがわかります。
公式リファレンスからも失敗時は手動対応か再試行の自動化が解決策に上がられているので、Step Functionsを利用した再試行の仕組みを導入しました。
ただStep Functions エラー処理を確認しても TaskFailedToStart のエラーはありません。
そのため、細かいエラー処理は独自のエラーハンドリングを作成することになります。
実装例
Lambda
Lambda Functionで補足したいエラー処理を実装しておきます。
Step FunctionsでRun Fargate Taskからの出力を変数に格納しておくことにより、Lambdaステップへの入力でその変数を使うことができるようになります。
この場合は result に格納しています。
class TaskFailedToStartException(Exception): pass
def error_handler(event, context):
if event.get("result").get("StopCode") == "TaskFailedToStart":
raise TaskFailedToStartException("TaskFailedToStart Error")
Step Functions
想定するワークフローを作成しておきます。
この例ではFargateタスクを実行し、その結果をハンドリングするといったフローになります。
Run Fargate Task での出力結果は成否に関わらず全て result に格納します。
result の内容から上記のLambda Functionでエラーを検出し、その結果から次のステップを選定しています。
再試行フローを実装するにはLambda を使用してループを反復するを参考にします。
"Run Fargate Task": {
"Type": "Task",
"Resource": "arn:aws:states:::ecs:runTask.sync",
略
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"ResultPath": "$.result",
"Next": "Error Handler"
}
],
"ResultPath": "$.result",
"Next": "Error Handler"
},
"Error Handler": {
"Type": "Task",
略
"Catch": [
{
"ErrorEquals": [
"TaskFailedToStartException"
],
"ResultPath": "$.result",
"Next": "捕捉時の処理"
}
],
"ResultPath": "$.result",
"Next": "次のステップへ"
},
CloudWatch Logs Insights
Fargate や Step Functions のログを分析用に利用しています。
既存バッチ処理ではEC2上にログを出力していましたが、コンテナ導入に伴い出力先をCloudWatch Logsに変更しました。
AWS上にログを溜め込むことにより一元管理することができたりログの集計がしやすくなります。
実行時間の長い処理などを一目で確認できるので処理の改善などに役立ちます。
CloudWatch Logs Insights を使用したログデータの分析には様々なログを解析できる仕組みが記載されています。
バッチ実行時間の集計の例
今まではEC2上に出力されていたログを確認していましたが、CloudWatch Logs上にログを集約することにより簡単に確認することができます。
下記はAWS Step Functionsの実行単位ごとに実行時間を集計してみた例となります。
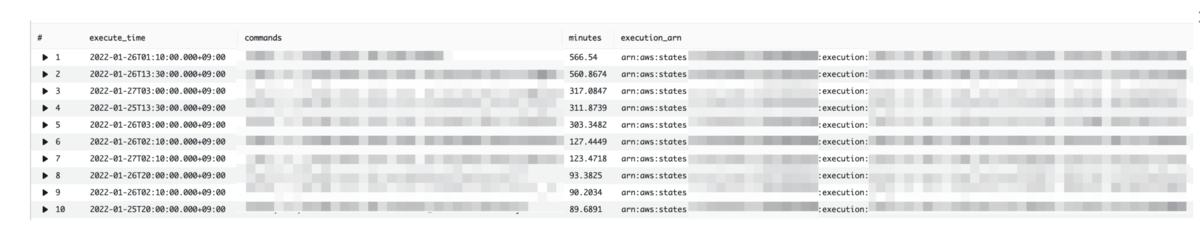
サンプルクエリ
対象はStep Functionsから出力されるログです。
クエリ構文に使い方が記載されているので参考になります。
fields @timestamp, execution_arn, details.output
| parse details.output '{"commands":[*]' as commands
| filter details.output like "commands"
| stats earliest(@timestamp) as startTime, latest(@timestamp) as endTime by commands, execution_arn
| fields abs(endTime - startTime) / 1000 / 60 as minutes, datefloor(startTime, 10m) as execute_time
| display execute_time, commands, minutes, execution_arn
| sort minutes desc
execution_arnはStep Functionsの一意の実行単位となるので、execution_arnごとの一番早いタイムスタンプと一番遅いタイムスタンプの差分を出します。
差分はミリ秒になっているので分単位に変換し可読性を上げます。
まとめ
サービス本体基盤へコンテナの導入をしてみました。
サーバレス化していくためには様々なマネージドサービスを利用します。
それぞれ使い方に特徴があって対策や活用事例などを探すのは大変ですが、導入すると運用コストを削減することができるので引き続き改善していきたいと思います。
最後に
ジモティーではエンジニアを募集中です!
jmty.co.jp
弊社では一緒にプロダクトを改善していただける仲間を探しています!
こちらでお気軽にお声がけください!